Wishing everyone a Happy New Year 2020.
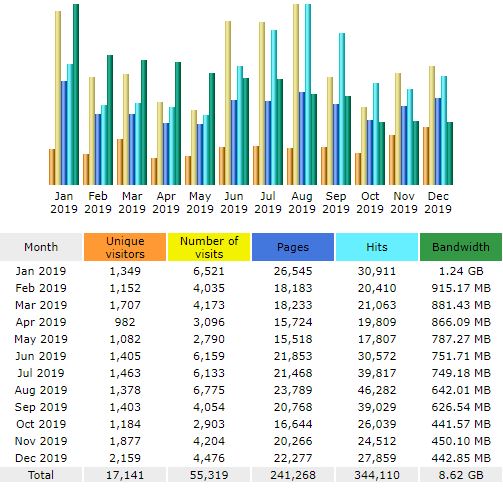
MOHANMA.COM recorded best numbers ever for a year in the calendar year 2019.
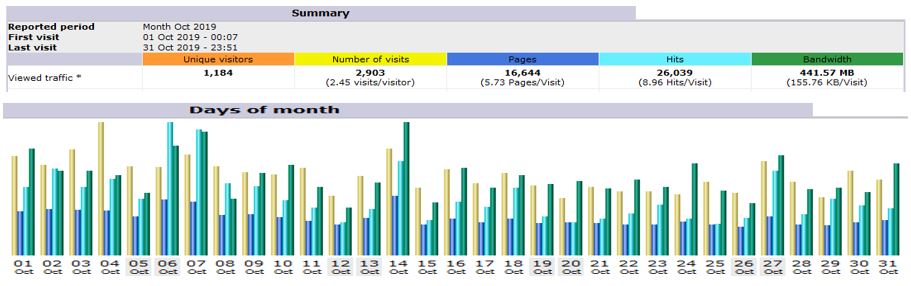
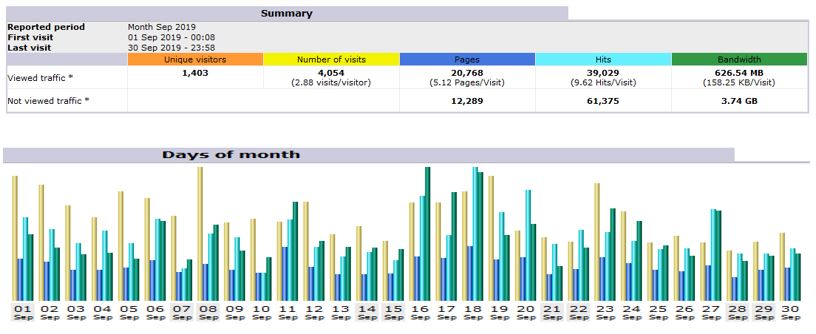
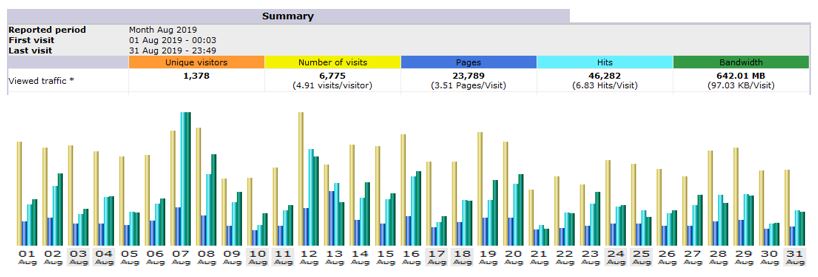
Total number of visits in 2019 was 55,319.
Total Hits in 2019 was 3,44,110.
Total number of unique visitors was 17,141.
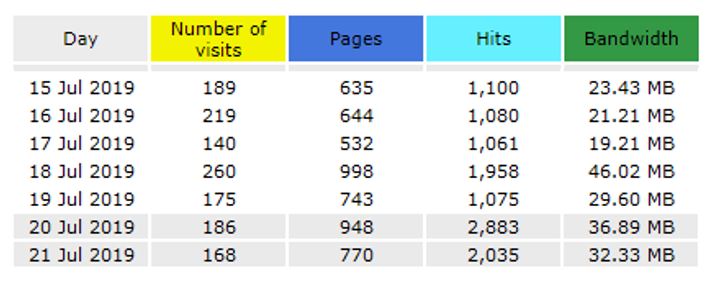
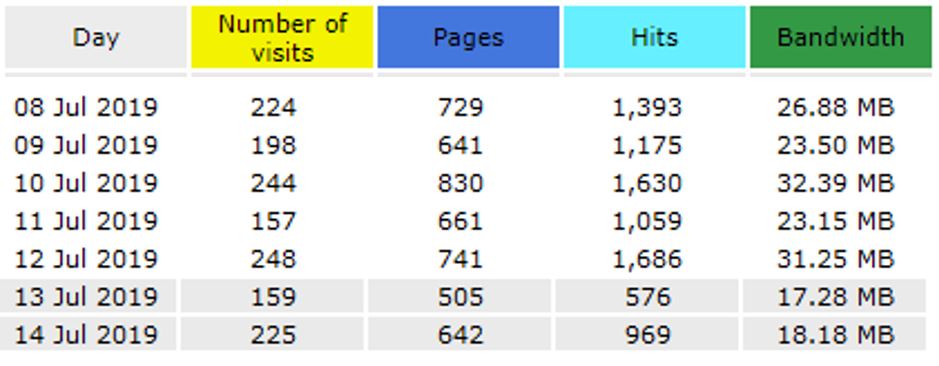
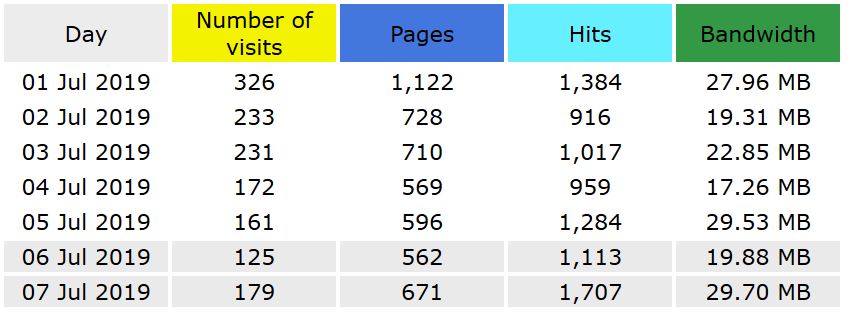
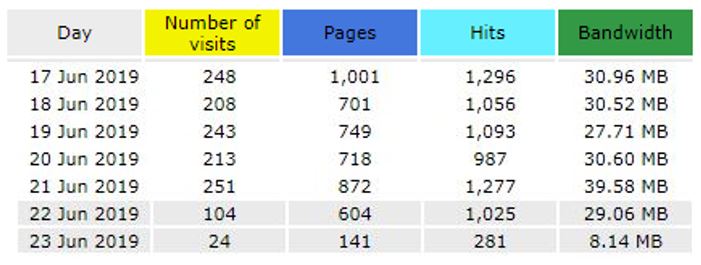
Please find below the statistics for December 2019.

December 2019 had the highest number of unique visitors in a month at 2,159.
Thank you all for visiting the website.