Apache Spark has a key feature known as Resilient distributed datasets(RDD’s). The data structure available in Spark.
RDD’s are fault tolerant and can be operated in parallel.
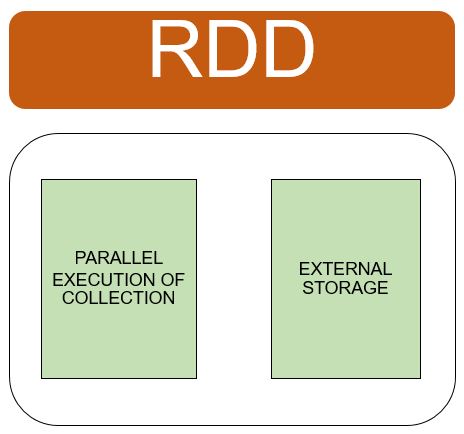
RDD’s can be created by:-
- Parallel execution of collection available in driver program.
- By referencing dataset in an external storage system such as HDFS, HBase or data source supporting Hadoop input format.
RDD’s support two types of operations:
- Transformations
- Actions
Transformations generate a new dataset from already available dataset.
Actions return values to driver after working on dataset.
Unlike Map-Reduce, Spark does not carry out the complete life-cycle of data processing for task completion.
Spark is efficient and operates on datasets only when results are required by driver program.