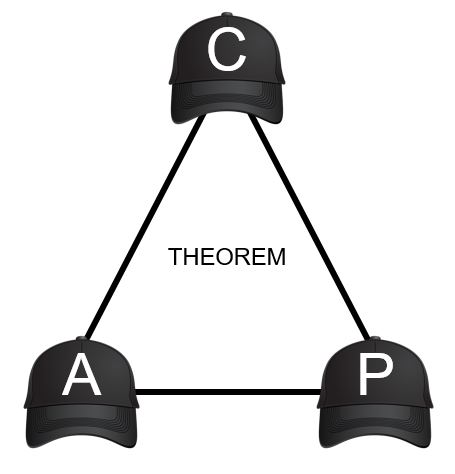
CAP Theorem is also known as Brewer’s Theorem.
CAP refers to Consistency, Availability and Partition tolerance.
- Consistency – All nodes in a cluster have same data at any particular time.
- Availability – It is the end result of request i.e. success or failure.
- Partition tolerance – As per this feature, the system continues to operate despite any hardware or network failures.
According to CAP Theorem any distributed system can exhibit only 2 out of the above 3 features.
Most distributed systems experience network failures, hence partition tolerance has to be met by distributed systems.
For the remaining one condition to be met:
Databases designed based on ACID properties choose consistency over availability.
Note: Consistency here not to be confused with the one in ACID.
On the other hand, databases designed based on BASE properties choose availability over consistency.
HBase
In case of HBase, consistency and partition tolerance are met. But HBase does not offer availability. HBase is a NoSQL database.