
 Data latency is the time taken to input the data into system or get the data present in the system.
Data latency is the time taken to input the data into system or get the data present in the system.
Data bit for the day – 24th June 2019
Understanding Apache Spark

In my last blog post I had discussed about data, now let us understand a modern tool to process huge datasets(BigData) so as to extract insights from data.
Apache Spark – A fast and general engine for large-scale data processing. Spark is a more sophisticated version of data processing engine compared to engines using MapReduce model.
One of the key feature with Apache Spark is Resilient distributed datasets(RDD’s). These are data structures available in Spark.
Spark can run on Hadoop YARN cluster. The biggest advantage to keep large datasets in memory adds to the capability of Spark over MapReduce.
Applications types that find Spark’s processing model helpful are:
- Iterative algorithms
- Interactive analysis
Other areas which make Spark more adoptable are:
Spark DAG(Directed Acyclic Graph) – This component of the engine helps to convert variable number of operations into a single job.
User Experience – Spark makes user experience smooth by having a plethora of API’s to perform data processing tasks.
Spark has API’s in these languages: Scala, Java, Python and R.
Spark programming comprising of the Spark shell(also known as Spark CLI or Spark REPL) makes it simple to work on datasets. REPL stands for read-eval-print loop.
Spark on the other hand provides modules for:
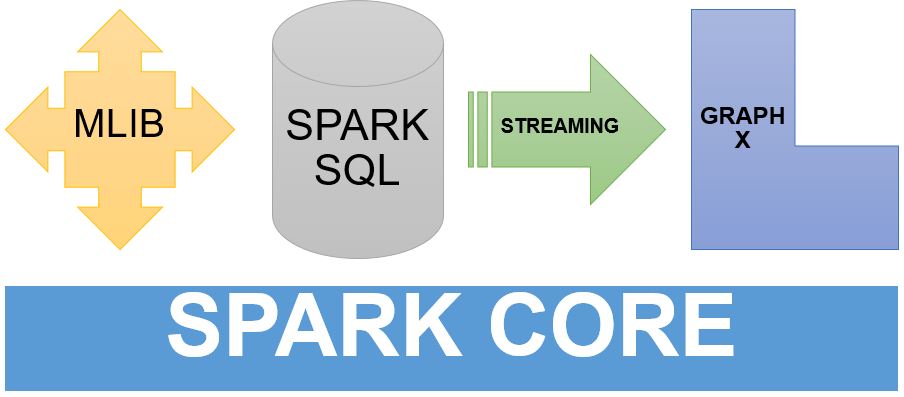
- Machine learning(MLib) – Provides a framework for distributed machine learning.
- Graph processing(Graphx) – Provides a framework for distributed graph processing.
- Stream processing(Spark Streaming) – Helpful for streaming(real-time) analytics. Data ingestion takes place in mini-batches and RDD transformations are performed upon these mini-batches.
- SQL(Spark SQL) – Provides data abstraction known as SchemaRDD which supports structured and semi-structured data.
These components operate on Spark core. Spark core provides platform for in memory computing and referencing datasets in external storage systems.
Companies that are using Apache Spark – Google, Facebook, Twitter, Amazon, Oracle, et al.
Spark services are provided on notable cloud platforms such as Google Cloud Platform(GCP), Amazon Web Services(AWS) and Microsoft Azure.
Source: Apache Spark
Data: The new “OIL” of Information Era

Anything and everything that can be produced, which we can quantify is referred as data. In simple words granular information is data. Automobiles and machinery have been running on oil extracted from earth. In the Internet age devices, machines and all mundane activities shall be driven by data.
All data that exists can be classified into three forms:
- Structured Data
- Semi-structured Data
- Unstructured Data
Structured Data – Structured data is a standardized format for providing information. Examples: Sensor data, machine generated data, etc.
Semi-structured Data – Semi structured Data does not exist in standard form but can be used to derive structured form with little effort. Examples: JSON, XML, etc.
Unstructured Data – Unstructured Data is any data that is not organized but may contain data which can be extracted. Examples: Social media data, Human languages, etc.
Most global tech giants operate from data generated by their users. Google, Amazon, Facebook, Uber, et al. come under the same umbrella. The insights derived from structured and semi structured data can help us in decision making. The magnitude and scale at which these companies generate data is astounding.
Databases play a very important role in storing data. But traditional databases are no longer a choice to store data in today’s fast moving world. New age file systems and infrastructure have started operating to cater the demands of ever expanding Internet space.
In the human world, the voice, speech, text, walking speed, everything can be classified as unstructured data, since we can derive a lot of insights from them. A mobile device per individual is pretty much sufficient to analyse the behavior of a sizable population in a region.
Data collected from a population for a relatively considerable time can be used to derive patterns about the population. Hence, data is the driving force which will fuel innovation and economy from here.