

Databricks – Developing Applications with Apache Spark

Databricks – Introduction to Apache Spark

Databricks – Advanced Spark Declarative

Spark
Data bit for the day – 5th October 2019
Data bit for the day – 3rd October 2019

Useful Transformations and Actions in Apache Spark
Transformations
groupByKey([numPartitions])
When called on a dataset of (K, V) pairs, returns a dataset of (K, Iterable<V>) pairs.
reduceByKey(func, [numPartitions])
When called on a dataset of (K, V) pairs, returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce function func, which must be of type (V,V) => V.
sortByKey([ascending], [numPartitions])
When called on a dataset of (K, V) pairs where K implements Ordered, returns a dataset of (K, V) pairs sorted by keys in ascending or descending order, as specified in the boolean ascending argument.
Actions
foreach(func)
Run a function func on each element of the dataset. This is usually done for side effects such as updating an Accumulator or interacting with external storage systems.
Source:Apache Spark
Understanding Apache Spark

In my last blog post I had discussed about data, now let us understand a modern tool to process huge datasets(BigData) so as to extract insights from data.
Apache Spark – A fast and general engine for large-scale data processing. Spark is a more sophisticated version of data processing engine compared to engines using MapReduce model.
One of the key feature with Apache Spark is Resilient distributed datasets(RDD’s). These are data structures available in Spark.
Spark can run on Hadoop YARN cluster. The biggest advantage to keep large datasets in memory adds to the capability of Spark over MapReduce.
Applications types that find Spark’s processing model helpful are:
- Iterative algorithms
- Interactive analysis
Other areas which make Spark more adoptable are:
Spark DAG(Directed Acyclic Graph) – This component of the engine helps to convert variable number of operations into a single job.
User Experience – Spark makes user experience smooth by having a plethora of API’s to perform data processing tasks.
Spark has API’s in these languages: Scala, Java, Python and R.
Spark programming comprising of the Spark shell(also known as Spark CLI or Spark REPL) makes it simple to work on datasets. REPL stands for read-eval-print loop.
Spark on the other hand provides modules for:
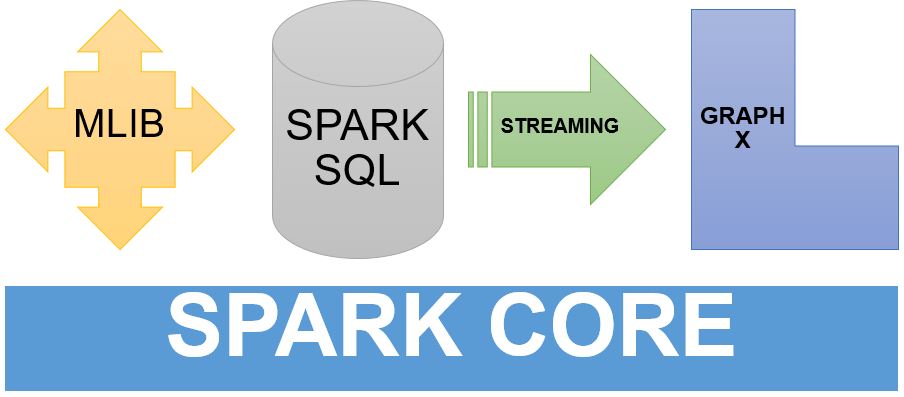
- Machine learning(MLib) – Provides a framework for distributed machine learning.
- Graph processing(Graphx) – Provides a framework for distributed graph processing.
- Stream processing(Spark Streaming) – Helpful for streaming(real-time) analytics. Data ingestion takes place in mini-batches and RDD transformations are performed upon these mini-batches.
- SQL(Spark SQL) – Provides data abstraction known as SchemaRDD which supports structured and semi-structured data.
These components operate on Spark core. Spark core provides platform for in memory computing and referencing datasets in external storage systems.
Companies that are using Apache Spark – Google, Facebook, Twitter, Amazon, Oracle, et al.
Spark services are provided on notable cloud platforms such as Google Cloud Platform(GCP), Amazon Web Services(AWS) and Microsoft Azure.
Source: Apache Spark