
Motivation yearns for consistency.
Quote for the day – 29th June 2019
Persistent approach to solve something results in a solution.
Universal love is an extremely strong force on earth.

Quote for the day – 27th June 2019
Acquiring new skills yields rich dividends.
Data bit for the day – 26th June 2019
Quote for the day – 26th June 2019
Courage is the only distinguishing factor among individuals of equal stature.
Quote for the day – 25th June 2019
To be acquainted with international culture is a modern norm.

Data bit for the day – 24th June 2019
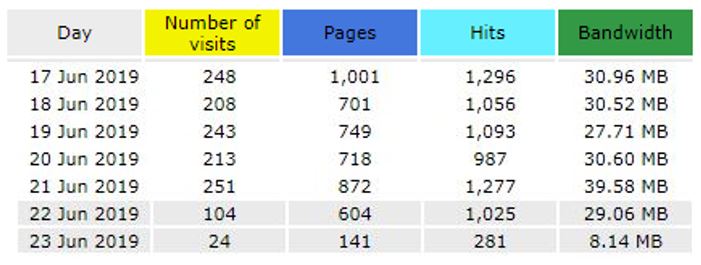
Statistics of Week 3 – 17th to 23rd June 2019 for MOHANMA.COM
Unique visitors for MOHANMA.COM inclusive of first three weeks of June 2019 is 1158.
Number of visits between June 17 to June 23 is 1291.
21st June 2019 had the highest number of visits – 251.
Average hits received per day is 1002.
Thanks to everyone who have been visiting the site.
Quote for the day – 24th June 2019
Think big start with one step and then compound your steps.
