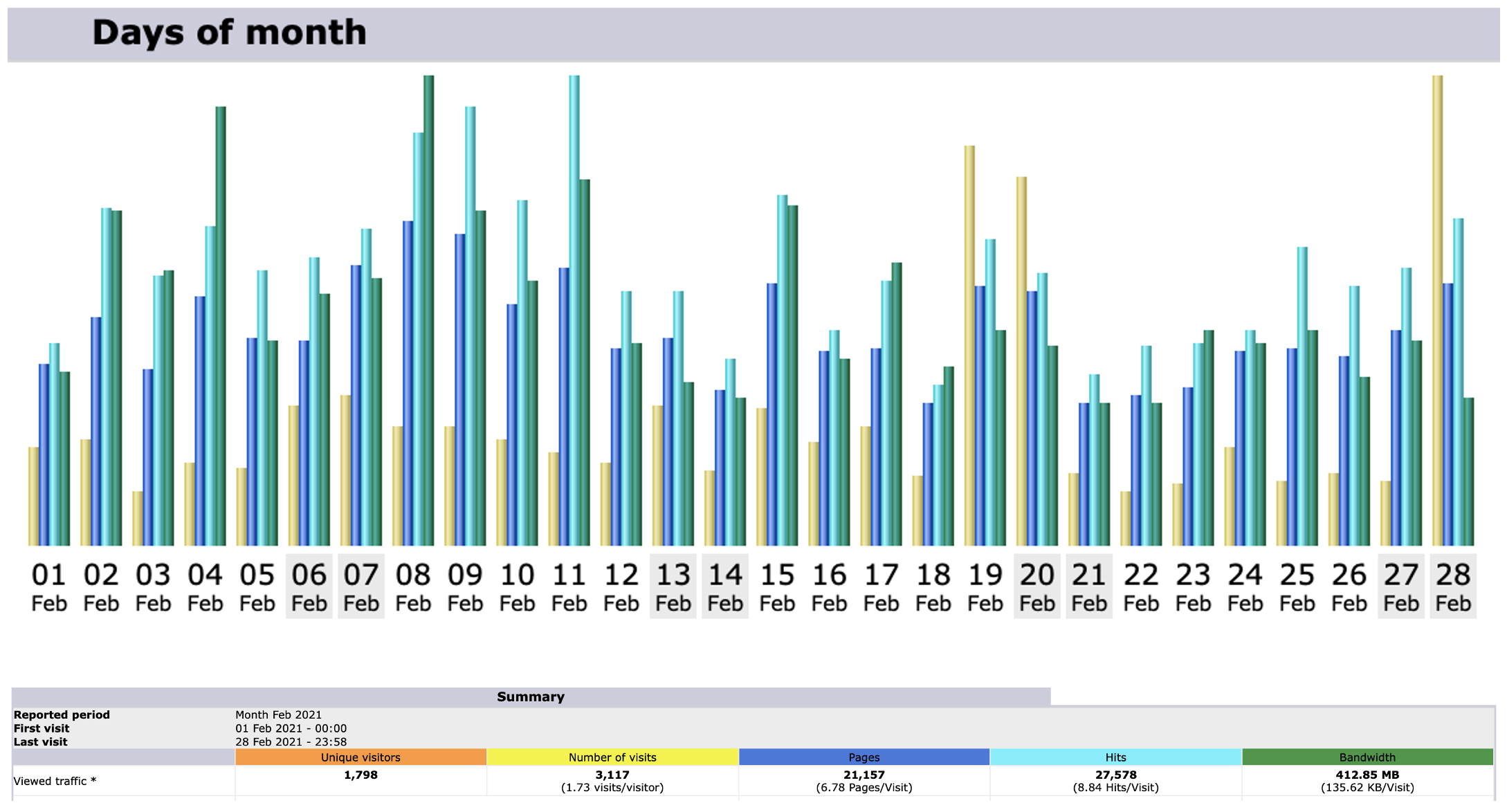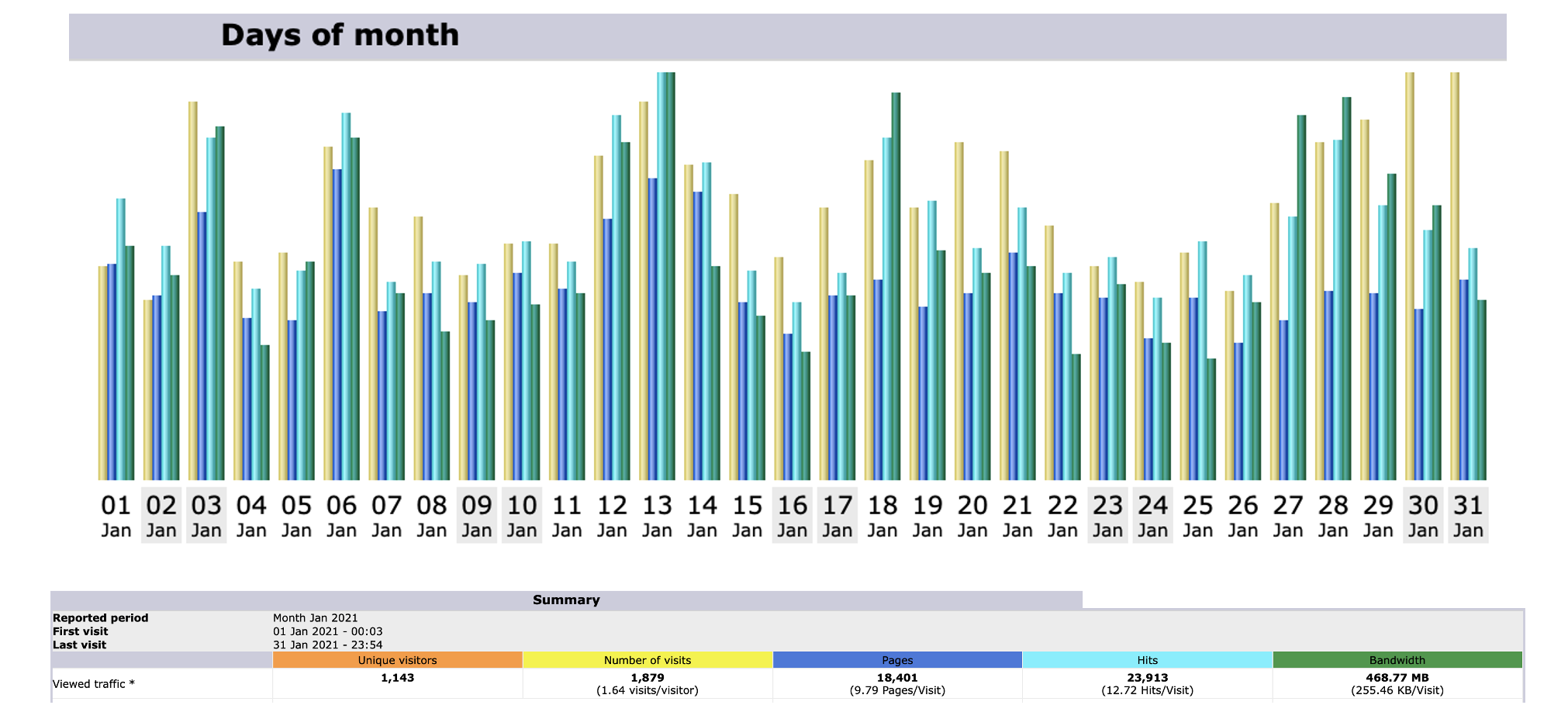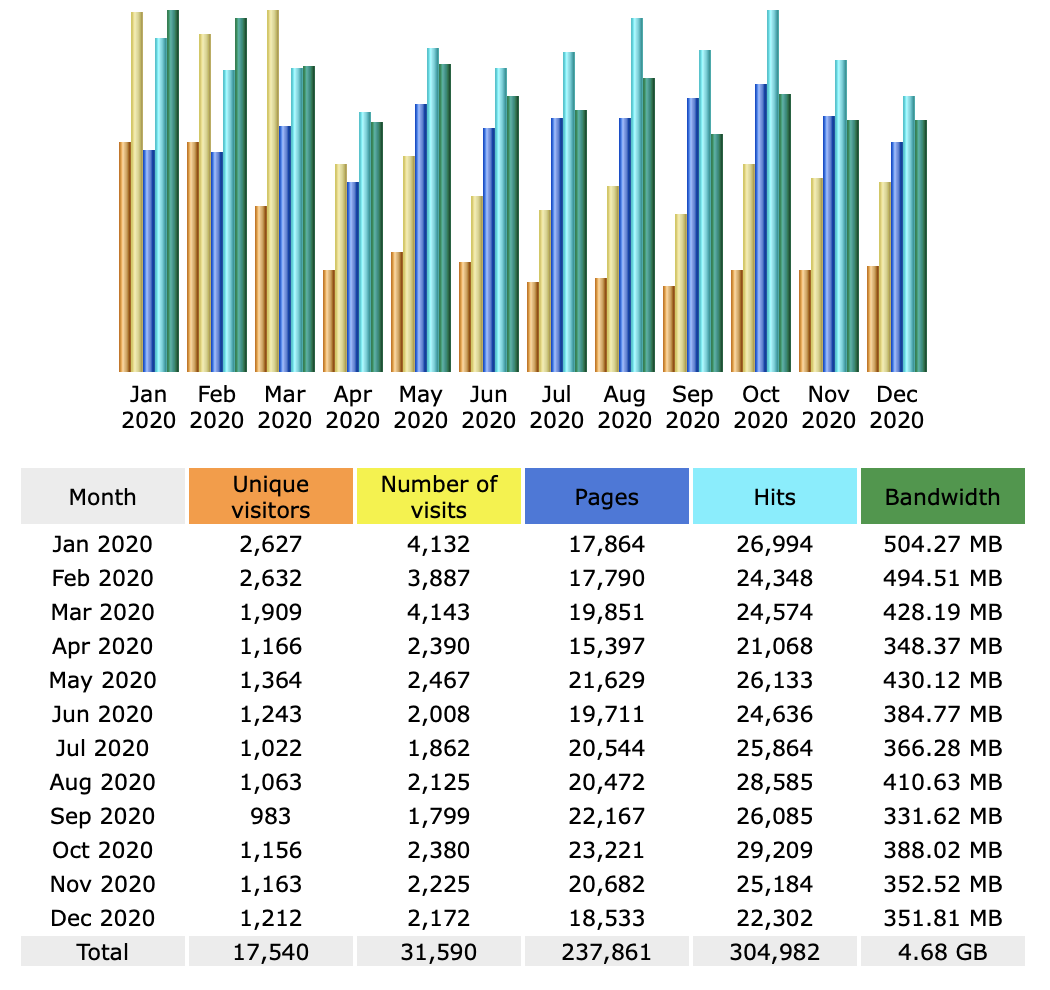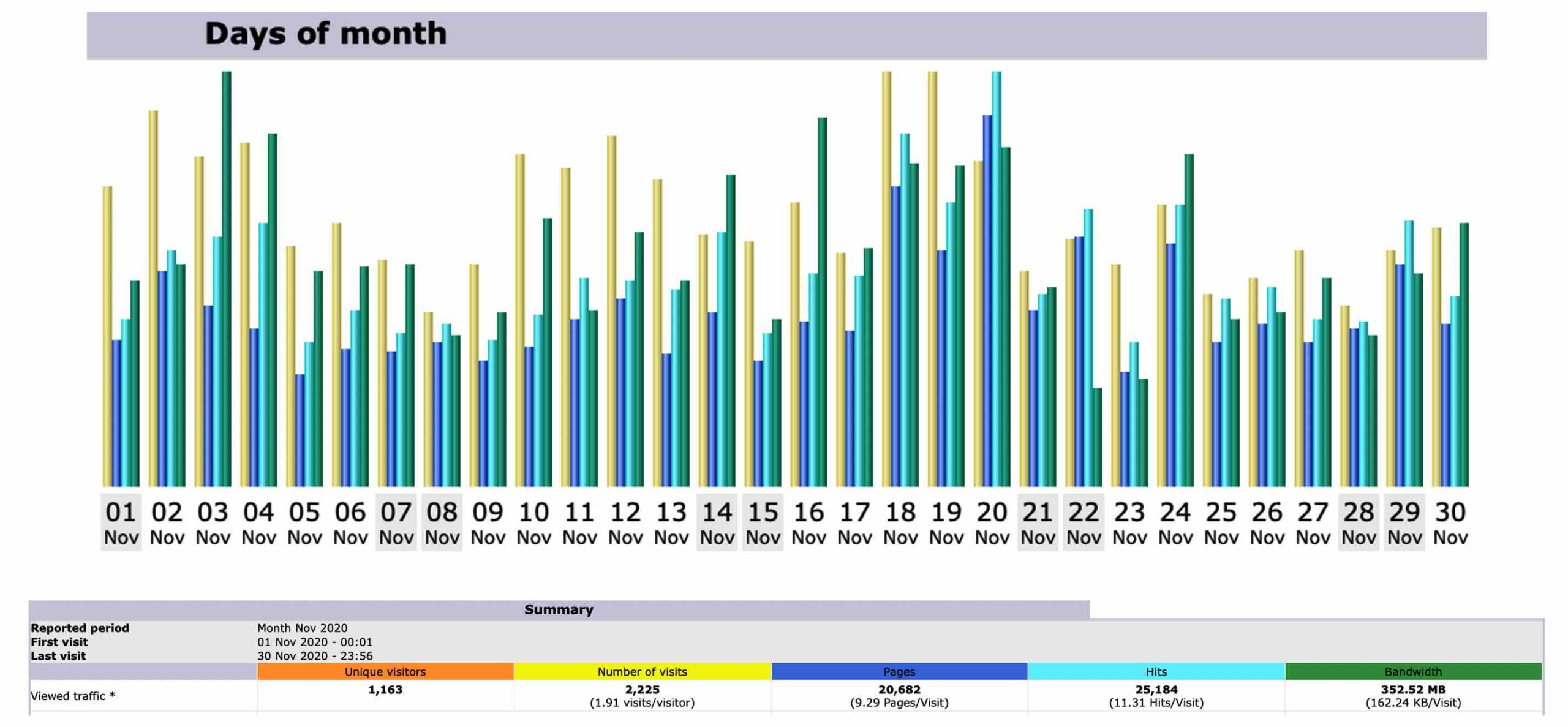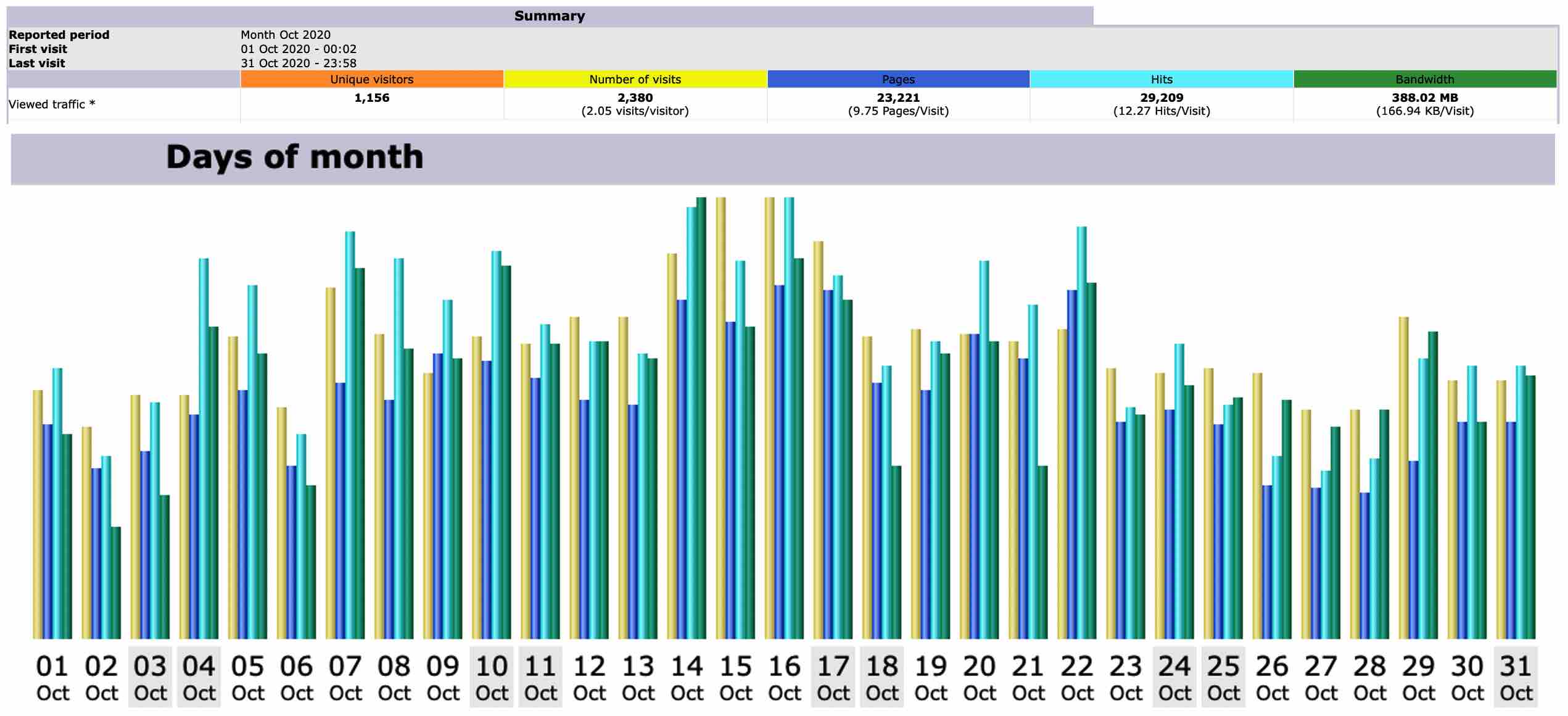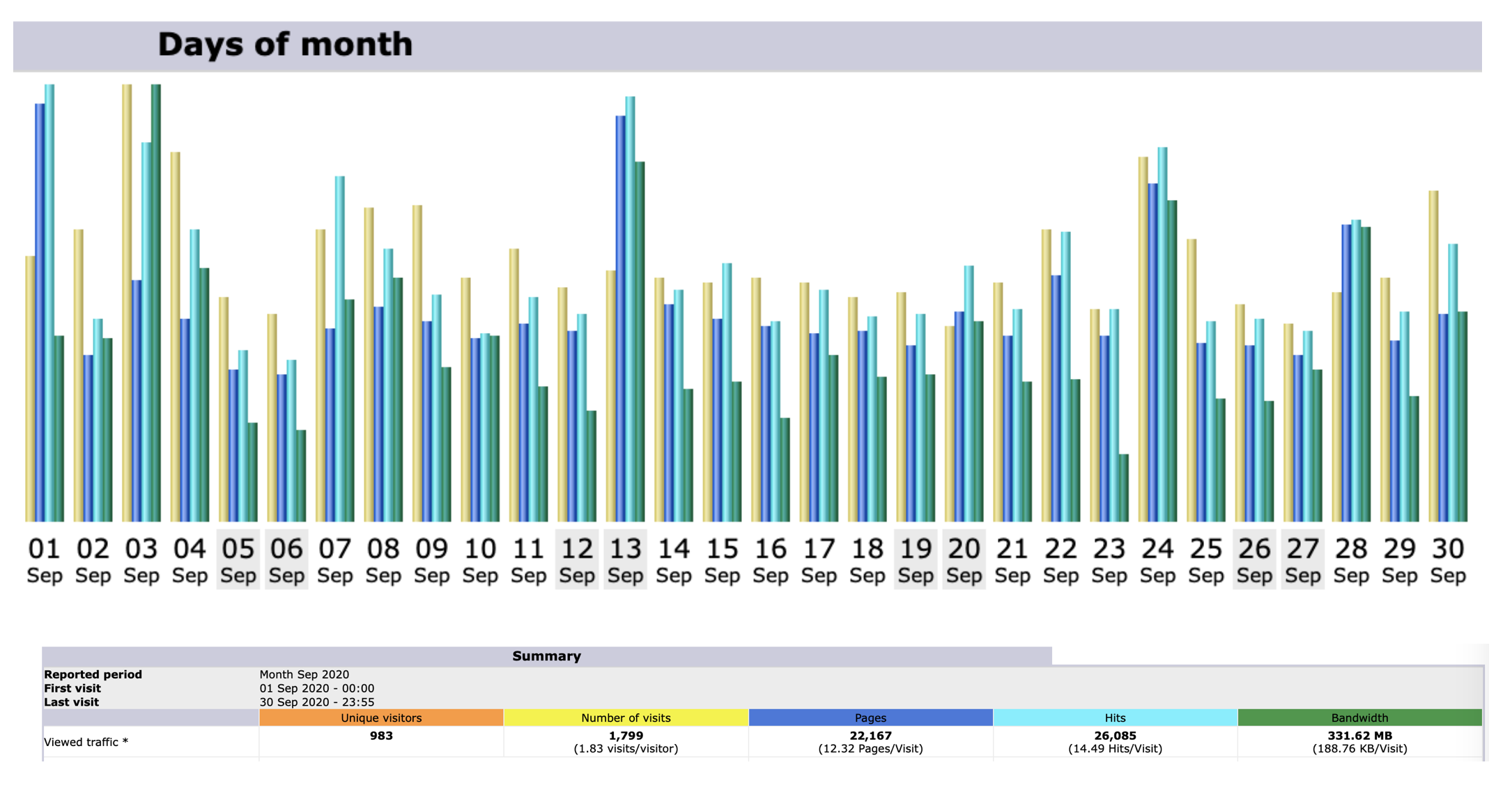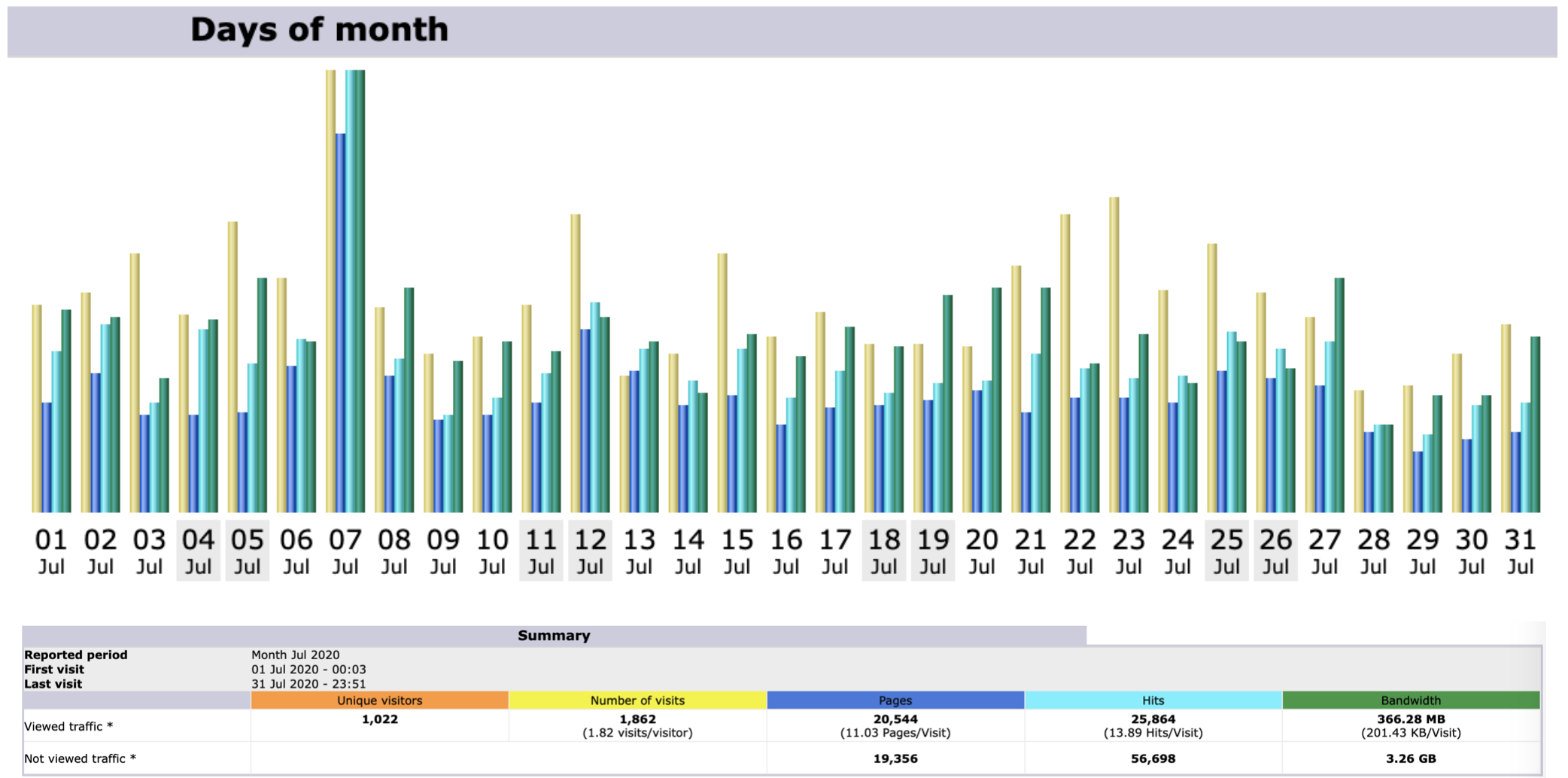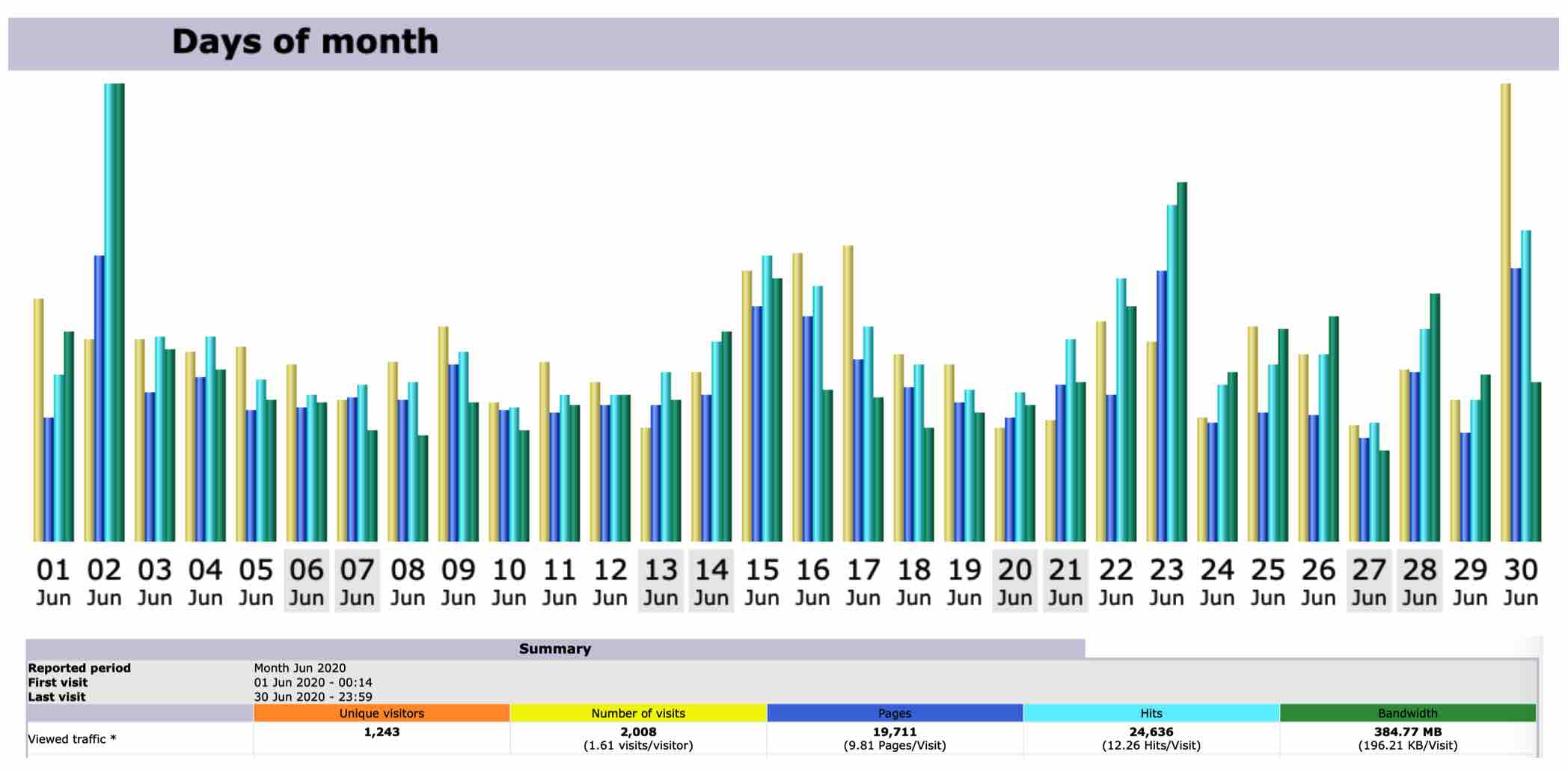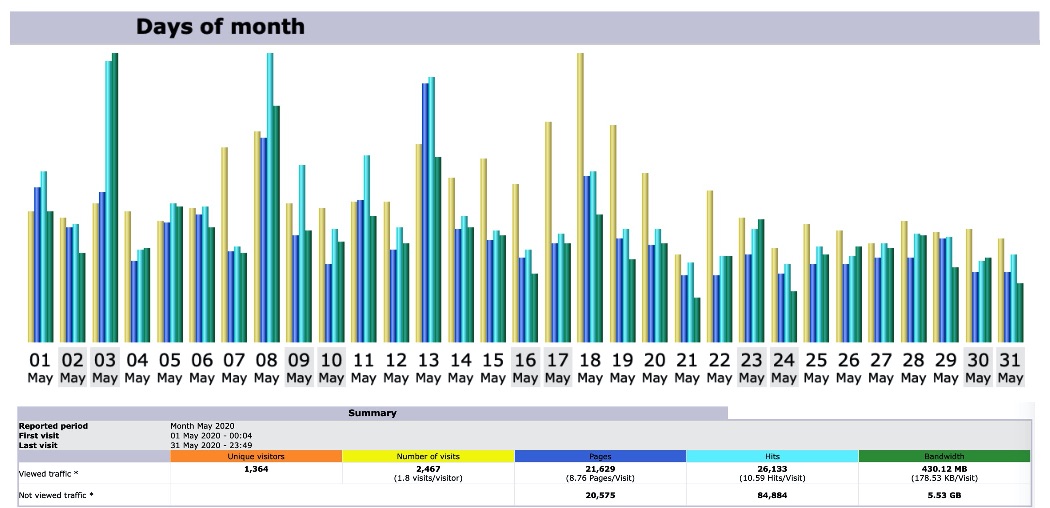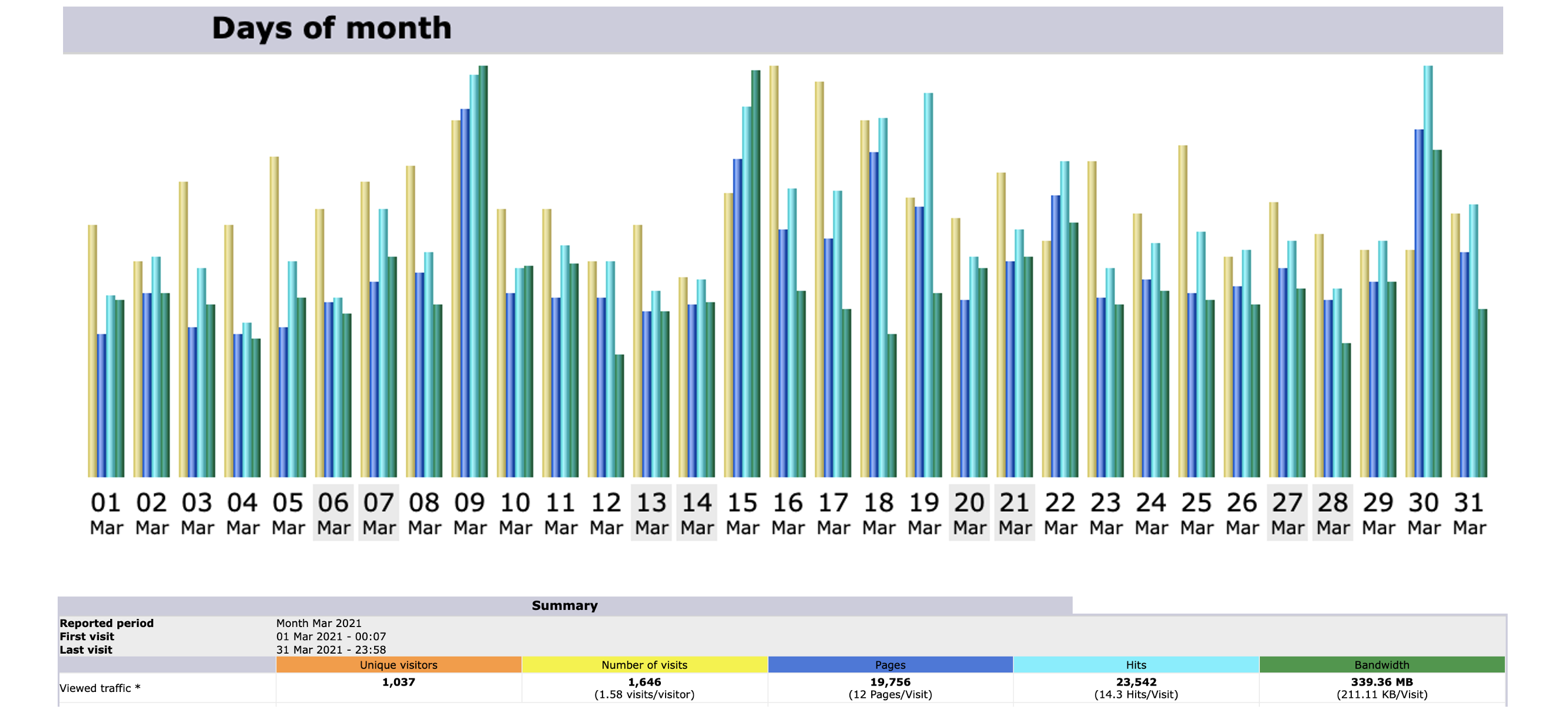
Stats for March 2021
Unique visitors for MOHANMA.COM in March 2021 is 1037.
Number of visits between March 1 to March 31 is 1646.
March 30th 2021 clocked the highest number of hits in a day for March 2021 – 1235.
Thank you all for visiting the website.